SimLex-999 is a gold standard resource for the evaluation of models that learn the meaning of words and concepts.
SimLex-999 provides a way of measuring how well models capture similarity, rather than relatedness or association. The scores in SimLex-999 therefore differ from other well-known evaluation datasets such as WordSim-353 (Finkelstein et al. 2002). The following two example pairs illustrate the difference - note that clothes are not similar to closets (different materials, function etc.), even though they are very much related:
| Pair | Simlex-999 rating | WordSim-353 rating |
| coast - shore | 9.00 | 9.10 |
| clothes - closet | 1.96 | 8.00 |
Our experiments indicate that SimLex-999 is challenging for computational models to replicate because, in order to perform well, they must learn to capture similarity independently of relatedness/association. This is hard because most language-based representation-learning models infer connections between concepts from their co-occurrence in corpora, and co-occurrence primarity reflects relatedness not similarity.
In addition to general-purpose evaluations of semantic models, SimLex-999 is structured to facilitate focused evaluations based around the following conceptual distinctions:
Download SimLex-999 by clicking here. All design details are outlined in the following paper (click to access). Please cite it if you use SimLex-999:
SimLex-999: Evaluating Semantic Models with (Genuine) Similarity Estimation. 2014. Felix Hill, Roi Reichart and Anna Korhonen. Computational Linguistics. 2015
Contact Felix Hill (felix.hill@cl.cam.ac.uk) if your questions are not addressed in the paper.
SimLex-999 is now in German, Italian and Russian thanks to Ira Leviant and Roi Reichart. See this page for more information.
SimLex-999 is now in Estonian thanks to Claudia Kittask and Eduard Barbu. See this page for more information.
The well-known Skipgram (Word2Vec) model trained on 1bn words of Wikipedia text achieves a Spearman Correlation of 0.37 with SimLex-999 [1].
The well-known Skipgram (Word2Vec) model trained on 1bn words of Wikipedia text achieves a Spearman Correlation of 0.37 with SimLex-999 [1].
The best performance of a model trained on running monolingual text is a Spearman Correlation of 0.56 [2].
A Neural Machine Translation Model (En->Fr) trained on a relatively small bilingual corpus achieves a Spearman Correlation of 0.52 [3].
A model that exploits curated knowledge-bases (WordNet, Framenet etc) can reach a Spearman Correlation of 0.58 [4].
NEW: A model that uses rich paraphrase data for training can reach a Spearman Correlation of 0.68 [5].
NEWER: A hybrid model trained on features from various word embeddings and two lexical databases achieves a Spearman Correlation of 0.76 [6].
NEWERER: Counterfitting works well [7].
The average pairwise Spearman correlation between two human raters is 0.67. However, it may be fairer to compare the performance of models with the average correlation of a human rater with the average of all the other raters. This number is 0.78.
Please email felix.hill@cl.cam.ac.uk if you know of better performing models.
[1] Efficient Estimation of Word Representations in Vector Space. Tomas Mikolov, Kai Chen, Greg Corrado and Jeffrey Dean. arXiv preprint arXiv:1301.3781. 2013.
[2] Symmetric Pattern Based Word Embeddings for Improved Word Similarity Prediction. Roy Schwarz, Roi Reichart and Ari Rappoport, CoNLL 2015.
[3] Embedding Word Similarity with Neural Machine Translation. Felix Hill, KyungHyun Cho, Sebastien Jean, Coline Devin and Yoshua Bengio. ICLR. 2015.
[4] Non-Distributional Word Vector Representations. Manaal Faruqui and Chris Dyer. ACL. 2015.
[5] From Paraphrase Database to Compositional Paraphrase Model and Back John Weiting, Mohit Bansal, Kevin Gimpel, Karen Livescu and Dan Roth. TACL 2015.
[6] Measuring semantic similarity of words using concept networks. Gabor Recski and Eszter Iklodi and Katalin Pajkossy and Andras Kornai. To appear in RepL4NLP 2016.
[7] Measuring semantic similarity of words using concept networks. Nikola Mrksic et al. Counter-fitting Word Vectors to Linguistic Constraints. EMNLP 2016.
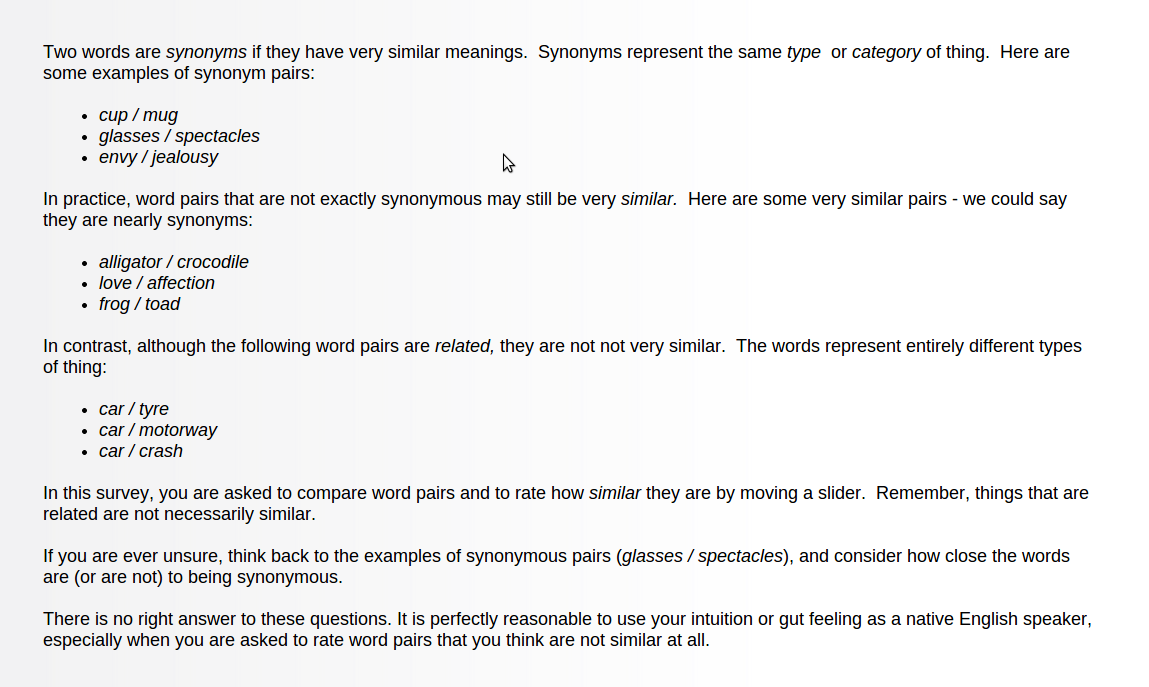
SimLex-999 was produced by mining the opinions of 500 annotators via Amazon Mechanical Turk. See below for annotator instructions.