Felix Hill

Research Scientist, DeepMind, London
Language Understanding Grounded in Perception and Action
My work aims to build computational models that exhiibit human-like understanding of language and its relation to perception and action.
In a less-than 30 min read I explain v simply Why Transformers are Obviously Good Models of Language.
I hope this is useful reading for anyone hoping to build language-based applications that human users value.
Recent work from the Grounded Language group at DeepMind
Multimodal few-shot learning with frozen language models
Click on the link above to donwload the evaluation datasets from our recent paper.
The systematicity and generalization of situated agents is enhanced by their rich learning experience; in particular their egocentric, first-person perspective.
With a dual-coding episodic memory system, situated language agents can learn new word-object bindings in a single shot, and integrate this knowledge into policies that lift and place those objects as instructed.
Large text-based language models can be adapted to exhibit similar fast visual binding (aka multimodal few-shot learning) using a simple Frozen method.
With a hierarchical memory system, agents can extend this ability in many ways, solving and generalizing over long-horizon binding tasks.
Situated language agents learn faster by exploiting multiple complementary learning algorithms, a notion inspired by human language learning.
Flexible spatio-temporal reasoning across three challenging tasks with a simple neural architecture based on soft-object embeddings, self-attention and self-supervised learning.
AGILE, an algorithm that jointly learns a instruction-conditioned reward function and a policy for realising that instruction. This provides a solution to a critical challenge for training agents to follow language commands; that the truth conditions of most linguistic expressions are typically very hard to express formally (e.g. in a programmed reward function).
Why situated language learning?
Children learn to understand language while learning to perceive, interact-with, explain and make predictions about the world around them. Our linguistic knowledge depends critically on sensory-motor and perceptual processes, which in turn are influenced and shaped by our language.
Our team at DeepMind has pioneered research into agents that learn the meaning of words and short phrases as they pertain to perceptual stimuli and complex action sequences in 3D worlds. These agents naturally compose known words to successfully interpret never-seen-before phrases, a trait that matches the productivity of human language understanding.
Understanding through perception, abstraction and analogy
A child might learn what growing means by observing a sibling, a pet or a plant get bigger, but once understood, the same idea of growing can be applied to pocket money, a tummy ache or Dad’s age. This ability to represent relations, principles or ideas like growing with sufficient abstraction that they can be flexibly (re-)applied in disparate, and potentially unfamiliar, contexts and domains is central to human cognition, analogical reasoning and language.
Colleagues and I have shown that neural networks that combine raw perception from pixels, together with components for reasoning across discrete sets of images, can exhibit strong analogical reasoning and impressive generalisation if trained in a particular way. Similar models can also be trained to solve visual reasoning tasks that challenge even the most able humans; our dataset of these problems is available for further research here.
Generalisation in neural networks
Models with strong inductive bias suited to a particular problem can exhibit impressive generalisation on domains related to that problem. On the other hand, more general architectures with greater variance may be effective on a wider range of problems, but may need a specific curriculum of training experience in order to exhibit strong generalisation. Hybrid approaches, such as our Neural Arithmetic Logic Unit, can represent the best of both worlds; the unit itself introduces a strong inductive bias suited to the extrapolation of numerical quantities, but models that include NALUs alongside conventional architectural components can retain general applicability to non-numerical problems as well.
Language understanding from text
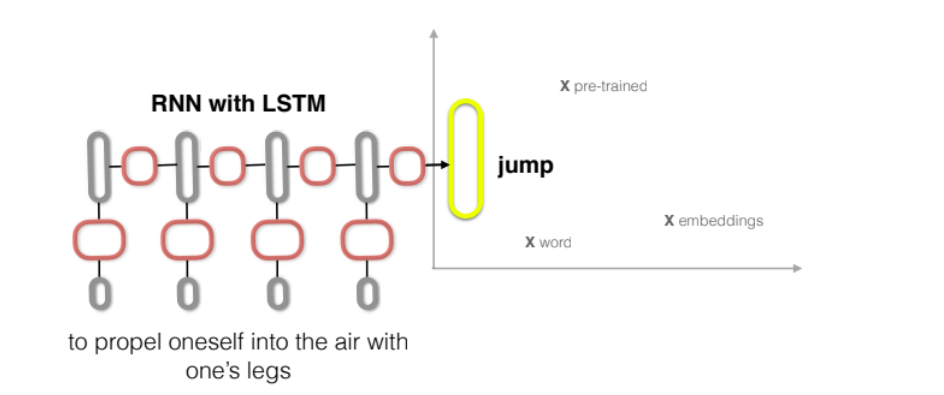
During my PhD, I worked with Anna Korhonen on ways to extract and represent meaning from text and other language data in distributed representations. I developed FastSent and Sequential Denoising Auto-Encoders, ways to learn sentence representations from unlabelled text. With Yoshua Bengio and Kyunghyun Cho, I noticed you can train a network on dictionary definitions to solve general-knowledge crosswords clues. With Jase Weston and Antoine Bordes I applied neural networks with external memory components to answer questions about passages in books. I also made SimLex-999 a way to measure how well distributed representations of words reflect human semantic intuitions, and recently helped to develop the GLUE benchmark for evaluating models of language understanding.
What about compositionality?
I think natural language is interesting because, unlike formal languages, mathematics or logic, it is isn’t in general compositional. Many people, on the other hand, say that language is interesting because it is compositional. My micro-blog NonCompositional that discusses some of these issues.
Teaching
With Steve Clark I taught a Master’s course Deep Learning for NLP at the Computer Laboratory, Cambridge University in 2018. If you follow that link you can find the synopsis, lecture slides and Tensorflow code for training neural networks on dictionary definitions. We got nice feedback, and hope to do the course again (somewhere) soon.
Videos and lectures
-
Deep Learning for NLP as part of the DeepMind UCL Lecture series.
-
Kenote address, Mexican International Meeting on Artificial Intelligence (in Spanish), August 2018.
Other stuff
I started doing cognitive science before I did any computational linguistics. And before that, I got Bachelors and Masters degrees in pure maths.
See Google Scholar for a list of publications.
When not working, things I like to do include football, running, yoga, travelling and relaxing.